Ordnung ist das halbe Leben – ein gut gemeinter Rat meiner Eltern und Großeltern. Doch gerade wenn es um die Unmengen an Dokumenten des täglichen Lebens geht, gestaltet sich dies oft schwierig. Verträge, Schriftverkehr mit Behörden, Rechnungen und sonstige Dokumente mit wichtigen Daten sammeln sich und füllen schnell die Schränke. Aber immer dann, wenn ich gerade mal irgendeine Kundennummer oder Ähnliches brauche, finde ich es erst nach langer Suche durch die Aktenordner.
Während dieser zeitintensiven Suchen, kam mir schon oft der Gedanke, mich einfach an einen Rechner zu setzen, meine gesuchte Information einzugeben und gezielt eine Antwort zu erhalten. Und nach vielen Aufschüben, habe ich mich mit dem Thema „Dokumentenmanagement“ beschäftigt, mit dem Ergebnis: Alfresco Community.
Alfresco Community
Alfresco Community ist eine ausgezeichnete Open Source Lösung zur Dokumentenverwaltung. Ein ausgereiftes, in Java entwickeltes System mit einer Unzahl an Funktionalitäten. Dazu gehört die Volltextsuche, die von Apache Lucene gestellt wird. Alfresco bietet die Möglichkeit eine Vielzahl an Dokumentenformaten zu indizieren, auch PDF. Jedoch besitzt es keine eingebaute Texterkennung (OCR genannt), um den Textinhalt aus Bildern zu extrahieren. Jedoch wiegen die vielen API’s und Protokolle, die Alfresco bereitstellt, diesen Mängel auf. Zusätzlich zum großen Umfang der Software, stehen viele Addons für die Erweiterung des Systems bereit.
Die Entscheidung fiel nach einer langen Suche in diesem Bereich und nach einigen Tests verschiedener Systeme. Ein großer Vorteil war hier der bestehende Docker Container. Er bietet einen unkomplizierten Quickstart des gesamten Dienstes, mit Ausnahme der Datenbank (MySQL ist standardmäßig eingestellt). So lässt sich das System sehr einfach zum Kennenlernen aufsetzen und schon kann man herumspielen. Letztendlich haben mich das Moderne Design und die hervorragende Volltextsuche überzeugt.
Das passende Arbeitsmittel
Um alle meine Dokumente zu digitalisieren, will ich nicht jedes einzelne Blatt Papier in einen Scanner einlegen. Das Mittel der Wahl ist ein Einzugsscanner. Dieser war auch ein Kaufgrund für den MFC-L2720DW. Leider hat dieses Modell keine Duplexeinheit für den Einzugsscanner. Jedoch war mir diese, keinen Aufschlag von 60€ wert, gerade weil die meisten meiner Dokumente nur einseitig bedruckt sind.
Mit diesem Scanner lassen sich problemlos bis zu 40 Seiten in 300dpi mit einem Lauf einscannen. Rein vom Platz her könnte er auch 55 Dokumente verarbeiten, aber ab 40-45 Seiten bricht er mit der Meldung „Speicher voll“ ab. Selbst mit 64 MB Speicher, stößt die Software bei der Verarbeitung der Rohdaten in das PDF-Format, an ihre Grenzen. Nichtsdestotrotz hat mich dieser Fakt während der gesamten Arbeit nicht behindert.
Idealerweise lassen sich FTP Profile mittels der Weboberfläche einrichten. Diese Profile bieten die Möglichkeit, neben den Zugangsdaten des FTP Servers, auch Scaneinstellungen vorzunehmen. Dazu zählt die Voreinstellung der Scangröße in dpi, die Farbeinstellung und das automatische Entfernen von Hintergrundrauschen. Dadurch bleibt lediglich die Eingabe der Dokumente und das Drücken des Startknopfs über.
Der ideale Workflow
Unter einem idealen Workflow für diese Aufgabe, stelle ich mir lediglich zwei Arbeitsschritte vor. Das Scannen der Dokumente und das Einsortieren in den passenden Ordner in Alfresco.
Ich wollte auf jeden Fall die manuelle Nachbearbeitung der PDF Daten vermeiden. Jedoch präferiere ich sogenannte „Sandwich-PDF’s“, die erzeugt werden müssen. Diese PDF’s bestehen aus zwei Ebenen pro Seite. Die obere, und damit sichtbare, Ebene zeigt das Bild wie es vom Scanner erfasst wurde. Die darunter liegende Ebene (unsichtbar) enthält die Daten der Texterkennung. Diese Daten umfassen den erkannten Text, an der ursprünglichen Position auf dem gescannten Bild. Dadurch lässt sich ein gesuchtes Wort an der korrekten Stelle auf dem Bild markieren.
Das Erzeugen dieser PDF Dokumente kann, wie eingangs erwähnt, nicht von Alfresco direkt übernommen werden. Aus diesem Grund habe ich einen Prozess entwickelt, der eingehende PDF Dokumente vom Scanner in das Zielformat konvertiert. Diesen Prozess habe ich in einen Docker Container verpackt, um ihn einfach ausliefern zu können. Da ich die Unix Philosophie sehr schätze, entwickle ich auch meine eigenen Lösungen danach. Ein Leitsatz dieser Philosophie ist: „Gestalte jedes Programm so, dass es eine Aufgabe gut erledigt.“. Aufgrund dessen ist dieser Container ausschließlich für die Erzeugung der Sandwich-PDF’s zuständig.
Um die erzeugten Sandwich-PDF’s in Alfresco abzulegen habe ich einen weiteren Prozess entwickelt. Dieser macht sich die REST-API des Alfresco Repositories zu nutze. Sein Ablauf ist simpel, er warte auf neue Dateien und importiert sie in einen konfigurierten Alfresco Ordner. Auch dieser Prozess wurde von mir in einem Docker Container verpackt.
Letztendlich habe ich den Workflow in einer Prozesskette mit Hilfe der drei Container verbunden. Den Scanner Container, den Alfresco Connector und den Alfresco Container.
Die Mechanik zwischen den Containern
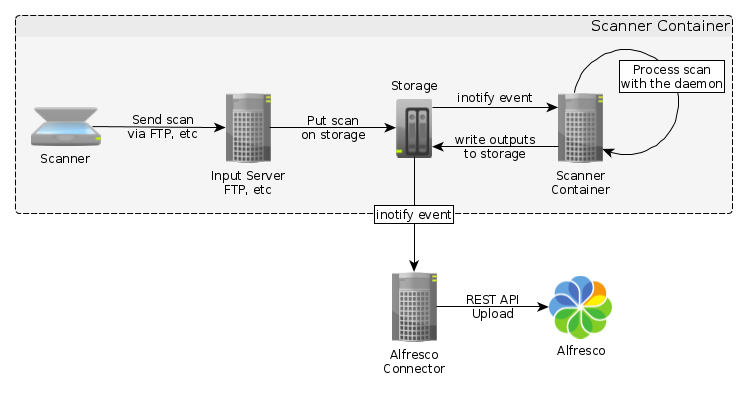
Dieses Diagramm beschreibt den kompletten Ablauf der Prozesskette. Der Scanner Container und der Alfresco Connector basieren auf dem inotify Linux Subsystem. Es dient der Überwachung von Verzeichnissen und Dateien, und kann Abonnenten mittels Events über Änderungen dieser informieren. Diese Container lassen sich einfach über Umgebungsvariablen konfigurieren.
Zusätzlich zu meinen eigenen Entwicklungen musste ich den bestehenden Docker Container für Alfresco mit einigen Änderungen neu verpacken. Leider ließ er sich nicht über Umgebungsvariablen konfigurieren, was ihn für den produktiven Einsatz unbrauchbar machte. Diese fehlende Funktionalität habe ich ihm auf Basis des bestehenden Containers beigebracht.
Die Container sind alle zusammen aus meinem e5 Server Projekt entsprungen und sind unter folgenden Adressen zu finden:
- Scanner Container Gitlab / Docker Registry
- Alfresco Connector Gitlab / Docker Registry
- Alfresco Container Gitlab / Docker Registry
Abschluss der Arbeit
Mit Hilfe des beschriebenen Systems, mit all seinen Komponenten, habe ich bereits über 700 Dokumente verarbeitet. Nun habe ich endlich alle wichtige Dokumente schnell zur Hand, ohne aufwendige Suchen. Ich hoffe es hat dem interessierten Leser gefallen. 😃